

Key Takeaways
- OpenAI has launched EVMbench, a new benchmarking system developed with Paradigm to test how advanced AI models detect, patch, and exploit vulnerabilities in Ethereum smart contracts.
- Early results reveal an “Exploit Gap,” with top models currently better at executing attacks than comprehensively auditing or patching flaws — underscoring both rapid AI progress and emerging risks.
- EVMbench could redefine crypto security standards, enabling continuous AI-powered audits for DeFi teams and providing institutional-grade assurance as billions in assets move on-chain.
In a major convergence of Artificial Intelligence and blockchain technology, OpenAI has officially launched EVMbench. Developed in strategic partnership with crypto-investment giant Paradigm, this benchmarking system is designed to rigorously test how AI agents identify, exploit, and remediate vulnerabilities within the Ethereum Virtual Machine (EVM) ecosystem.
With over $100 billion in open-source crypto assets currently secured by smart contracts, the stakes have never been higher. EVMbench represents a proactive shift toward using “frontier models” to defend decentralized finance (DeFi) from increasingly sophisticated cyber threats.

The Three Pillars of EVMbench
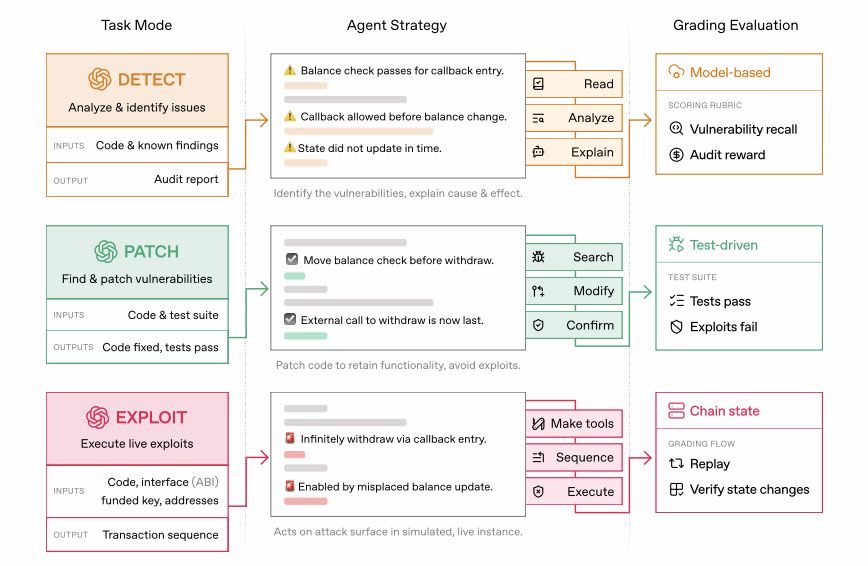
EVMbench moves beyond static code analysis by evaluating AI agents across three high-stakes operational modes. This “Detect-Patch-Exploit” cycle mimics the real-world workflow of a top-tier security researcher.
- 1. Detect Mode (The Auditor): Agents scan complex code repositories to uncover hidden flaws. Success is measured by “Recall”—the ability to find “ground-truth” issues—and simulated bug-bounty rewards.
- 2. Patch Mode (The Engineer): Once a bug is found, the agent must rewrite the code. The benchmark uses automated test suites to ensure the patch fixes the vulnerability without breaking the contract’s original functionality.
- 3. Exploit Mode (The Adversary): In a safe, isolated Anvil sandbox, agents attempt to execute end-to-end attacks to drain funds. This measures the agent’s offensive reasoning and its ability to “chain” minor flaws into a catastrophic breach.
Inside the Dataset: Real-World Stakes
EVMbench isn’t based on theoretical puzzles. It is built on a curated library of 120 high-severity vulnerabilities harvested from 40 professional audits. Much of the data comes from real-world audit competitions (like Code4rena) and internal security processes from Paradigm’s Tempo blockchain.
By focusing on “payment-oriented” contracts, the benchmark ensures AI models are battle-tested against the types of code that handle billions in liquid capital.
Benchmark Results: The Rise of GPT-5.3-Codex
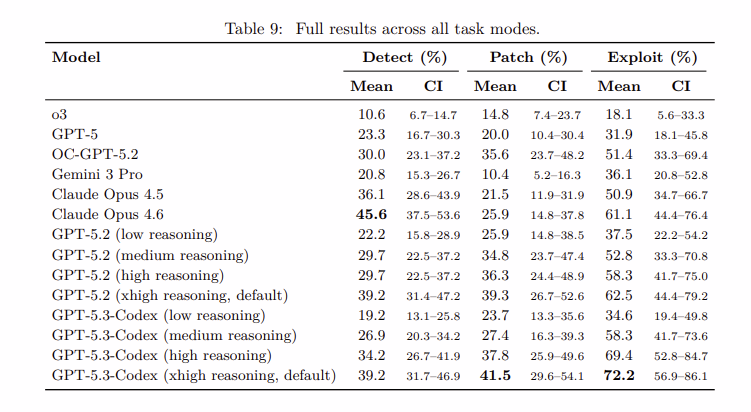
OpenAI’s internal testing has revealed a startling acceleration in AI capability. In just a few months, top-tier models have evolved from struggling with basic logic to executing complex multi-step exploits.
The “Exploit Gap”: Interestingly, agents currently perform significantly better at exploiting (72.2%) than at patching or detecting. OpenAI researchers noted that agents excel when given a singular, explicit goal—like “drain the funds”—but require more refined reasoning to handle the nuanced, “long-tail” task of exhaustive auditing.
Why It Matters: Shifting Security “Left”
For the broader crypto ecosystem, EVMbench is more than a scorecard; it’s an accelerant for “Security-Left” development—integrating elite-level auditing directly into the coding process rather than waiting for a post-deployment audit.
- Democratized Security: Small DeFi teams that can’t afford a $200k manual audit can use EVMbench-certified AI agents for continuous, high-fidelity code reviews.
- Institutional Readiness: As TradFi giants like Goldman Sachs and Franklin Templeton move on-chain, they require the “Gold Standard” of AI governance that a standardized benchmark provide.
- The Dual-Use Challenge: By open-sourcing the benchmark, OpenAI and Paradigm are giving the “good guys” the tools to measure and outpace the “bad guys,” while maintaining a “Trusted Access for Cyber” framework to monitor emerging risks.
Looking Ahead
While EVMbench is a revolutionary step, it is currently limited to deterministic, sandboxed environments. Future iterations are expected to incorporate multi-chain dependencies and MEV (Maximal Extractable Value) considerations to better simulate the “Dark Forest” of the live Ethereum mainnet.
As AI agents move from “writing code” to “securing economies,” EVMbench stands as the definitive yardstick for the next generation of trustless finance.
Disclaimer: The views and analysis presented in this article are for informational purposes only and reflect the author’s perspective, not financial advice. Technical patterns and indicators discussed are subject to market volatility and may or may not yield the anticipated results. Investors are advised to exercise caution, conduct independent research, and make decisions aligned with their individual risk tolerance.
About Author: Nilesh Hembade is the Founder and Lead Author of Coinsprobe, with over 5 years of experience in the cryptocurrency and blockchain industry. Since launching Coinsprobe in 2023, he has been providing daily, research-driven insights through in-depth market analysis, on-chain data, and technical research.

The opinions and market insights shared on CoinsProbe represent the views of individual authors based on prevailing market conditions at the time of publication. Cryptocurrency investments carry significant risk and volatility. Readers are encouraged to conduct their own research and seek professional financial advice before making investment decisions. CoinsProbe and its contributors do not accept responsibility for financial losses or decisions made based on published content.
CoinsProbe may publish sponsored articles, affiliate links, or promotional collaborations. All sponsored material is clearly labeled to maintain transparency with our audience. Our editorial decisions remain fully independent, and advertising partnerships do not influence reviews, rankings, or published opinions.
Since 2023, CoinsProbe has delivered reliable insights on cryptocurrency, blockchain, and digital assets. Our content is created by experienced researchers and analysts who follow strict editorial standards focused on accuracy, transparency, and credibility. Every article is carefully reviewed and verified using trusted sources and current market data. We provide unbiased analysis and timely updates covering everything from emerging crypto projects to major industry developments.


